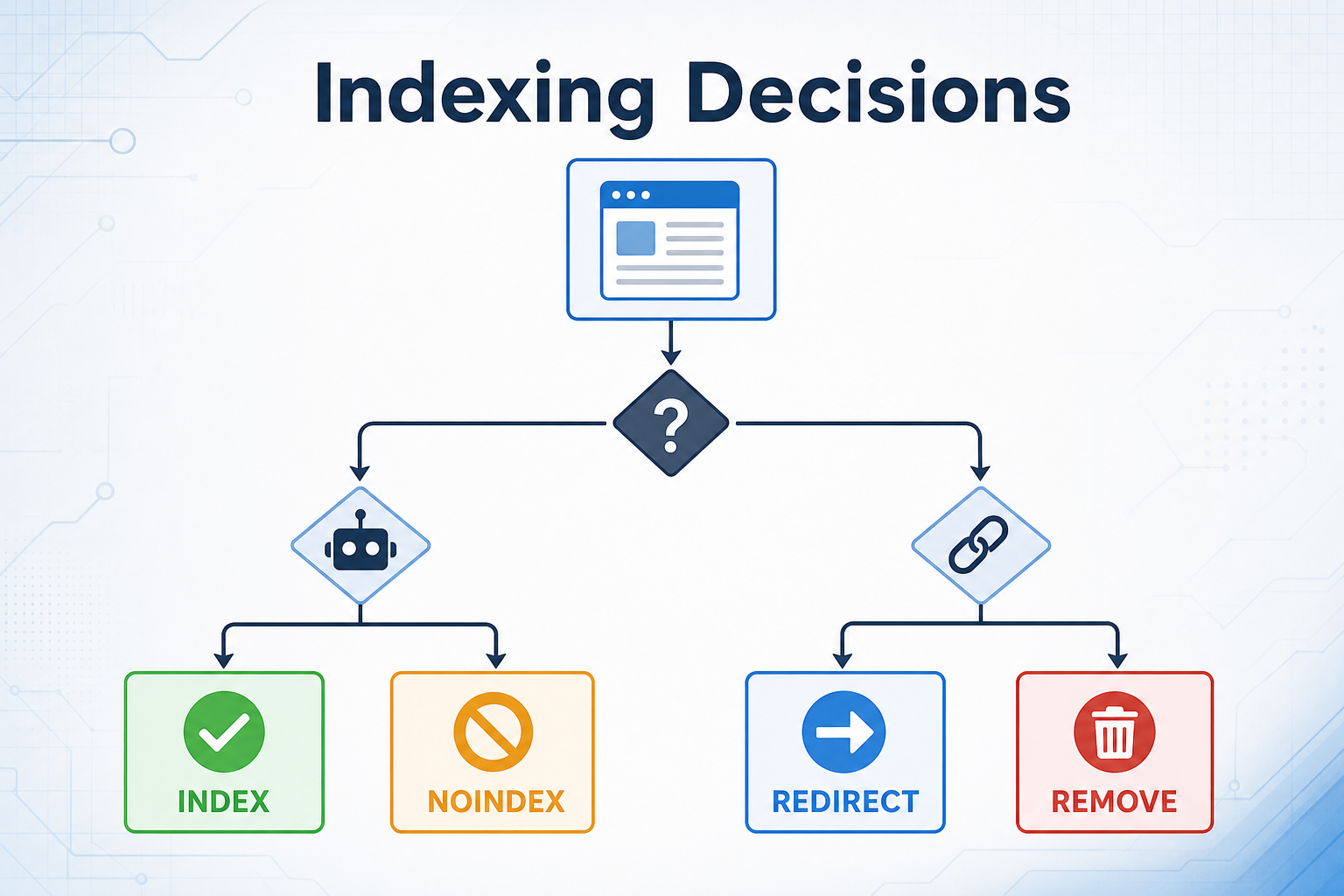
Robots directives are not a content strategy. They are a way to express indexation decisions after you have decided what the site should publish. Site quality problems often begin when every URL is allowed to index by default, even when many pages are filters, placeholders, thin variants, or policy pages with no search purpose.
A healthy site has fewer accidental public pages. It knows which URLs should be discovered, which should be indexed, which should consolidate, and which should stay out of search. That discipline helps search engines and visitors understand the site more quickly.
How this guide is reviewed
This guide is maintained by the toolhubapk editorial team for the metadata generator workflow. We review the page against the visible tool behavior, linked official sources when policy or search behavior is mentioned, and the examples a reader may adapt before publishing a real page.
The reviewed date changes only when the guide, examples, sources, sitemap entry, or related tool behavior receives a meaningful update.
Key takeaways
- Use indexable pages for URLs that have a unique purpose and enough visible content.
- Use noindex for public pages that should be accessible but not search results.
- Use robots.txt for crawl control, not as a private content system.
- Use redirects or removals when a page has no lasting reason to exist.
Separate crawling from indexing
Robots.txt tells compliant crawlers where they should not crawl. A robots meta tag tells search systems how to treat a fetched page. These are different tools. Blocking a URL in robots.txt can prevent a crawler from seeing a noindex directive on the page. That is why noindex usually belongs in the page head or response header for pages that remain publicly reachable.
For small publisher sites, the simpler question is often enough: do we want this page in search results? If yes, it needs content value and internal links. If no, it should be intentionally excluded or removed from public paths.
- Index: unique public content with a reason to rank.
- Noindex: accessible utility pages, internal search pages, or thin support flows.
- Robots.txt disallow: crawl budget or sensitive path management, not privacy.
- Redirect: replaced pages with a clear successor.
Do not index pages just because they exist
Modern frameworks make it easy to create pages. That does not mean every page should be indexed. A tag page with one article, a search page with no query, a legal page duplicated from a template, or a generated city page with swapped names can all make a site look thinner than it is.
Indexation should be earned by usefulness. If a page cannot answer a specific user need better than another page on the site, improve it, merge it, or keep it out of the sitemap.
Internal search page
Allow /search to index with no query and thin results.
Keep /search accessible for users, but exclude empty or internal search-result pages from the sitemap and use noindex when needed.
Use sitemaps as a quality list
A sitemap is not a dump of every route. It is a curated list of canonical URLs you want crawlers to discover and review. If a URL appears in the sitemap, it should be ready for evaluation. That means status 200, canonical alignment, useful content, unique metadata, and internal support.
For public launch preparation, treat the sitemap as your evidence package. It should show a focused site with real pages, not a thin skeleton with a few content URLs and many policy or utility pages.
Create an indexing review cadence
Indexation decisions change. A page that was useful at launch can become outdated. A policy page can change when tracking changes. A guide can need updates when platform behavior changes. Review your important URLs on a schedule and record the last reviewed date on the page or in a content inventory.
This cadence is a quality signal for users too. A page with a current reviewed date, clear authorship, and maintained examples feels safer than a page that looks abandoned.
Pre-publish checklist
- Every sitemap URL has a clear search or user purpose.
- No accidental internal search, filter, preview, or placeholder pages are in the sitemap.
- Noindex is used on accessible pages that should not appear in search.
- Robots.txt does not block crawlers from seeing pages that need noindex.
- Old, merged, or weak URLs are redirected, removed, or improved deliberately.